
update 2024-02-11 :
话说是不是在这里加一个目录啊,字数已经 3w+ 了欸。
总览
妙用 $\text{stable_sort}$ $+$ 数据接近有序的排序
发现答案有分化然后用二分加速枚举
省略不必要的状态加速递归,类似二分
以身入局的贪心非常直观
从最为容易的决策入手一步步考虑贡献贪心(一般是从最终到初始)
从题目展现出特殊的地方入手
从简单的状态开始考虑倒推
手玩数据 | 补图与原图相关性质
考虑问题是否具有特殊性质,如序列必定连续等
爆搜剪枝
利用 bitset 存储二进制状态,考虑限制转换
$1-24$
$\small{对排序算法的理解}$
$\large{\text{Solution}}:$
挺有意思的一题,原先按照题意模拟考虑轮用一次 $\text{sort}$ 没想到时限太紧 $\color{darkblue} T$ 了( $O(R\cdot n\log n)$ 确实慢),但是根据题解的思想直接把 $\text{sort}$ 换成 $\text{stable_sort}$ 居然过了???
题解思路,考虑胜者每轮都 $+1$ ,负者每轮都不变,因此 胜者所在的集合内部 和 负者所在的集合内部 分数的相对大小关系是不变的,都是有序的。因此问题转化成了将胜负二者这两个有序数列合并的问题,可以采用 $O(n)$ 的归并排序中的方法来合并,总体复杂度 $O(R\cdot n)$。
$\small{二分加速枚举、线段树、若干水法}$
$\large{\text{Solution1}}:$
可以发现每次区间操作后这段区间的数都会变得更小,因此若一次操作后区间序列不合法(有数字 $<0$)那么之后的所有操作序列都不再合法;同理,若一次操作后序列仍合法,那么这个操作前的序列也必定合法。这就满足了二分的局部舍弃性(或者是单调性?),可以用一个二分来加速操作的枚举。
具体的,对于每一个 $\text{mid}$ , 都判断执行了 $\text{mid}$ 个操作后序列是否合法,以此二分。
$\large{\text{Solution2}}:$
先处理出完成 $m$ 次操作的序列,然后 $1-n$ 扫一遍,若当前数 $<0$ 那么将操作从后往前依次撤回,直到整个序列都合法,那么最后一次撤回的操作即为答案。
P3612 [USACO17JAN] Secret Cow Code S
$\small{递归(分治)}$
$\large{\text{Solution}}:$
可以看出每次操作后的字符串后半部分与上一次的字符串基本一样,所以我们就考虑用这个来递归,每次都会缩小一半的长度。
具体的,若 $n<\frac{len}{2}$,那么后半部分是没用的,直接 $len/2$;若 $n>\frac{len}{2}$ ,那么位置 $n$ 是由上一个串的位置 $n-1-len/2$ 翻转得到,递归处理这个子问题即可。
$1-25$
$贪心,带一点博弈论?$
思考加代码总用时约 1 小时,代码错误:局部变量未初始化,导致UB。
$\large{\text{Solution}}:$
不管我们开局选哪个武将 $x$,和他默契度最高的武将 $y$ 一定会被电脑抢走。但是默契度次大的武将 $z$ 我们必然可以取到。因此,全部武将对应默契次大值的最大值即为我们的最优解,同时我们根据机器策略的盲目性,显然可以主动的避免让机器取得优于我们的解,因此人类必胜。
$贪心$
刚开始想了10+分钟有了接近正解的思路,但是没有沉住气继续深入思考就直接开始 coding,导致接下来硬钢 90 分钟无果,然后继续深入思考后想出正解,10分钟写完代码。
$\large{\text{Solution1}}:$
显然 $x=n$ 时答案是易得的,而转移到 $n-1$ 只需删除一个对答案贡献最小的数即可。因此本题使用倒推,维护每个数的贡献,然后每次小根堆删除最小的即可。因为要删数,所以我们还需要一个链表维护前一个数 $lst_i$ 和后一个数 $nxt_i$。
考虑 $i$ 的贡献:若 $S_i$ 不是当前未删数字的最大值,那么 $S_i$ 对答案没有贡献,此时 $i$ 的贡献
为 $a_i$;若 $S_i$ 是最大值,那么删除掉 $i$ 会使得答案失去 $S_i-S_{lst_i}$ 这一段,所以此时 $i$ 的贡献为 $2\cdot(S_i-S_{lst_i})+a_i$。由于每一次删数都有可能导致 $S_i$ 的最大值改变,而且 $lst_i$ 也在变,因此在删的过程中还有进一步维护每个数的贡献。
$\large{\text{Solution2}}:$
距离很烦,所以我们先不考虑距离 ——题解
选 $x$ 个,最贪心的想,按照 $a$ 排序选前 $x$ 大的那几个。其次,我们可以通过将其中的一个(显然也只需要一个)换成另一个 $S$ 更大的数,也就是用 $a$ 的贡献换取 $S$ 的贡献,也可能让答案更优。至于用哪个来换呢,显然使用最小的,也就是第 $x$ 大的来换。
这题确实挺不错的。
$1-26$
$数学,构造$
找到了解题的关键但是没有深入思考,导致20分钟后宣告失败,遂看题解。
$\large{\text{Solution}}:$
三个变量让我很不喜欢,所以考虑先干掉一个
注意到 $\dfrac{2}{n}$ 的这个 $2$ 似乎别有用意,于是尝试把它拆成 $\dfrac{1}{n}+\dfrac{1}{n}$,原式变为
不妨直接令 $z=n$,则问题化为求
然后就是小学奥数 $\dfrac{1}{n+1}+\dfrac{1}{n(n+1)}=\dfrac{1}{n}$ 结束。
闲话:实在太菜了,做黄色的构造题都觉得好难QAQ
$构造$
AGC 的题目果然不一般,非常有趣,思路中的细节值得深入思考。思考20分钟无果,遂看题解。
$\large{\text{Solution}}:$
考虑什么时候无解:一个数 $a$ 肯定是在位置 $a$ 处插入,而往后的插入操作每次都会把一部分数往后推,因此最终序列 $b$ 有 $b_i\le i$,否则无解。
最后一次插入是容易的,肯定是一个数 $i$ 插入到了位置 $i$ 上。于是我们从后往前找到第一个 $b_i=i$ 的数,那么他就是最后一次插入操作,把它撤销后序列就变成了上一次操作时的,就变成了子问题,继续找即可。
为什么要从后往前呢?考虑若有 $b_x=x,b_y=y,x
还是没做出黄题,寄。
$图论,构造$
在草稿纸上模拟了10分钟就想出来了,大概是构造一个各部分权值和相同的完全 $k$ 分图(参加OI-wiki),算是比较友好的题了。
题解的思路非常有参考价值。
$\large{\text{Solution}}:$
若无向图(无重边无自环)$G$ 不连通,则它的补图 $G’$ 联通。
上述结论的证明 在这里
我们构造一个图,使得此图
- 不连通
- 对于图上的任意顶点,该点和与该点相连的点编号和均为定值 $S$
那么这张图的补图就满足
- 连通
- 对于图上的任意顶点,与该点相连的点编号和均为定值
可见满足了题目要求。
具体的,我们将 $n$ 分奇偶讨论:
若 $n$ 为奇数,那么我们将连接 $(1,n-1),(2,n-2)\cdots$ ,$n$ 单独一点。输出补图即可。
若 $n$ 为偶数,我们连接 $(1,n),(2,n-1)\cdots$,输出补图即可。
看到了个有趣的 $trick$:不降原则——枚举的时候有序枚举,保证序列不降,可以去重
$1-27$
$记忆化搜索,贪心$
记搜部分水爆了,但是第二问的前提性质还是挺有思考价值的,证出来以后贪心就做完了。
$\large{\text{Solution}}:$
无解的情况搜索的时候直接判掉就好了,下面只考虑有解的情况。
性质:蓄水池能到的干旱地区一定是一个区间
证明的话可以用反证法巴拉巴拉胡一下,大概就是两条不同的路径必有交叉,因此能输水的地方必定连续(没有图不好描述)
记搜的时候就把蓄水池能到的区间左右端点记下来即可,然后第二问就变成了一个区间覆盖整条线段问题,贪心即可。
具体的,将区间按照左端点排序,每次选都选一个左端点在已覆盖范围内且右端点最远的区间来更新。参考
$搜索剪枝$
没写,但是其中有一个剪枝非常巧妙。
因该是最优化剪枝的一种,思想就是若当前操作是最优的但还是失败了,那就没必要继续往后尝试了,回溯到以前即可。
具体到本题,就是若选上当前木棍恰好能凑出一根完整木棍(这个操作显然是所有可选操作中最优的),但是往后搜索还是失败了,那就没必要继续尝试用别的木棍凑这根原始木棍了,回溯到上一层。
P3067 [USACO12OPEN] Balanced Cow Subsets G
$Meetinmiddle$,$bitset$
非常暴力的思路,思考加coding反反复复一共花了90min,最后用bitset直接贴着最优解的脸。
看了一下题解,思路很巧妙(果然我太蠢了),但是貌似并没有我快(普遍做法 1s,我的做法 200ms)
$\large{\text{Solution1}}:$
很暴力的思想,先枚举子集,然后再枚举子集的划分!
数据规模很小但是暴搜又过不了,于是可以考虑折半暴搜搜索。直接把序列分成左右两半,然后分别dfs选子集。
考虑左半部分选出了子集 $A$,将它分为两部分和分别为 $a$,$b$,右半部分选出了子集 $B$,将它分为两部分和分别为 $c$,$d$ ,若两个子集的并为 $C$ ,要使 $C$ 合法则应有 $a+c=b+d$,移项可得 $a-b=d-c$ 。
这就给我们折半后合并答案提供了思路:我们选定出子集后同样暴力搜索出它的划分方案,称两部分权值的差为 $A-B$,然后用一个 $set$ (当然是为了去重)记录下每个集合所有可能划分的 $A-B$ 的值,合并时利用 $set$ 保存的信息,判断有多少个左右集合的某个 $A-B$ 值相同,这些是对答案有贡献的。
具体实现有一点复杂,使用了 bitset 来去重,跑得飞快。
$\large{\text{Solution2}}:$
题解巧妙的做法在于:每个数有三种状态,一种是不选,一种是放入1队,最后是放入2队,一个dfs就可以 $O(3^n)$。
果然比我的先枚举子集,再枚举子集中的划分这种两层dfs要清新多了,统计答案的时候也是记录 $A-B$ ,也是将子集二进制压缩来去重(我用的是bitset),感觉大差不差,不知道为什么有些题解比我慢那么多。
$1-28$
$\large{\text{Solution}}:$
LIS 中用二分维护的 d 数组的意义是维护对于每个DP值得最优转移,比如说求不升子序列的时候,将 $a_i$ 接在一个恰好 大于他的位置是最优的(小了不行,大太多也浪费),而可以证明这个最优的位置是单调的,因此可以二分维护。
主要就是这什么 $Dilworth$ 定理:在偏序集中,最小链划分数等于最大反链的长度。
说人话就是,将一个序列划分为多个不相交的不升子序列,最小划分数是这个序列最长上升子序列的长度。
$1-29~\&~30$
众所周知,蓝色是水的颜色,这就是一道DP翻译题。(指把题意翻译成DP的转移就过了)
$\large{\text{Solution}}:$
每个木头相互独立,而每个格子只能涂一次,因此不难想到把他们设入状态。
设 $f_{i,j,k,0/1/2}$ 表示涂了 $j$ 次涂到第 $i$ 块木板的第 $k$ 格时,涂 $0$ 或 $1$ 或不涂的最大正确数。
然后就有了显而易见的转移,只需要分讨填到第 $k$ 个的时候的决策即可(翻译题目)。
特别的,有初值
大水,建议降绿
$贪心,构造$
半年前月赛里的黄题,不会做,现在还是不会做,果然我一点没有长进。评价是该死的贪心。
$\large{\text{Solution}}:$
首先求出每个节点的深度,若深度和 $sum$ 为奇数显然无解。
问题可以转化为选出某些节点,使其深度和恰好等于 $\dfrac{sum}{2}$。考虑到本题一个很重要的性质:因为在树上,因此深度在值域上是连续的。,注意到这一点就可以很容易想到必定是凑出 $\dfrac{sum}{2}$。
具体的,我们贪心从大到小扫过去,若可以选就选上,否则找更小的补。
当然如果直接写一个暴搜程序,加上从大到小的排序也是能过的,因为大的数太僵硬不好分配所以先选,小的数灵活可以尽可能满足条件。这个操作可以非常有效的减小搜索树的规模。
$1-31$
月末,遇到了一道神仙题,这道题警示我不要在一个困难的思路上死磕,要像广搜一样,接受一些悦动的新灵感,或许会有不一样的收获。
P2501 [HAOI2006] 数字序列 题解
$DP+找性质$
sb题调了3个小时,确实神仙细节也确实多:(
$\large{\text{Solution}}:$
先看第一问,要求最少改变多少个,其实不太好下手(但是我还是下手了,硬写了快1小时的DP,真蠢啊),考虑补集转化,其实就是求最多保留多少个。手玩一下数据找找性质可以发现,因为要求最后要严格上升,所以若 $a_i-a_j<i-j$,那么 $a_i$ 和 $a_j$ 不能都保留,因为无法改变他两中间的那些数使得这个区间上升(中间数字太多,可用数字太少)。所以设 $f_i$ 表示保留 $i$ 则 $1$ 到 $i$ 中最多能保留多少个数,易得
但是如果把限制移一下项,就会得到 $a_i-i\ge a_j-j$,若设 $b_i=a_i-i$,那么上述转移就是在求 $b$ 的最长不下降子序列!恭喜你找到本题的性质之一,可以愉快的用 $O(n\log n)$ 做掉第一问。
获得成就:得到 $b$ 数组。
现在看第二问,显然修改 $a_i$ 和修改 $b_i$ 是等价的,因此就转化为了用最小的修改代价使得 $b$ 单调不降。
需要修改的显然是不在最长不降子序列中的数。若 $b_i~,~b_j~(j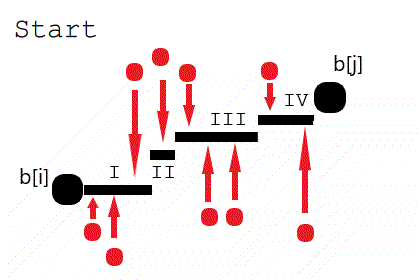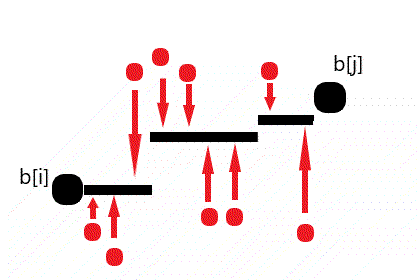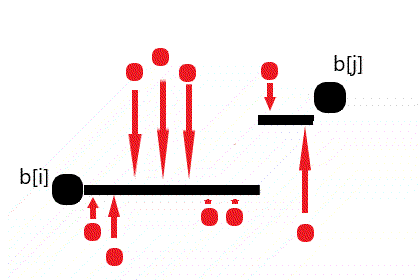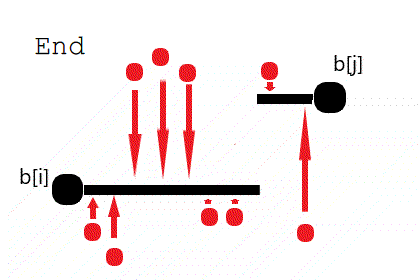
由图可知且可以证明任何最小代价的阶梯样式一定能被转换为上图所示的 ⌊ 存在一个划分点 $k\in[i,j]$,使得 $\forall l\in[i,k],b_l=b_i~and~\forall l \in (k,j],b_l=b_j$ ⌉ 的形式。
因此我们只需要枚举分界点 $k$ 即可找到最小代价。
需要注意,最长不降子序列可能有多个,因此最终求答案的过程还需 DP。设 $g_i$ 表示保持 $b_i$ 不变,使得 $[1,i]$ 不降的最小代价。若 $b_i$ 在最长不降子序列中的前一个数是 $pre_i$ (显然,$pre_i$ 可能不是 1 个数),那么有
利用前缀和和数据随机的特性,该算法为 $O(n^2)$ 。
实现细节就非常有东西了,因为正常情况下最长不降子序列的左右两边都可能有数,因此我们要将 $b_0$ 和 $b_{n+1}$ 分别做最小和最大处理,将他们也纳入不降序列当中。其中,$b_0$ 不能直接设成0,因为 $b_i$ 的值域可以达到 $-n$(两个小时的 experience)。
P2946 [USACO09MAR] Cow Frisbee Team S
$\large{\text{Solution}}:$
考虑从限制入手,要让所选数的和为 $F$ 的倍数,形式化的转换一下就是 $\bmod F=0$,因此可以想到把 $\bmod F$ 写入状态,然后就是一个选与不选的DP方程了。
若有代价和价值以及一个限制,那么考虑背包。
背包是一种对(代价,价值)二元关系的合并方式,因此树上DP对子树的合并也即是背包。
$2-1$
又打了一场比赛,遇见了一道有趣的题。
$\large{\text{Solution}}:$
二进制好题。
在题解里学会了一个好用的玩意
所以题目就转化为了找 $x~\operatorname{xor}~y=A-2B$,按二进制位考虑,就能发现除最高位有贡献外其他位都是互补没有贡献的,然后这题就做完了。思路即清爽又引人深思,痛快!
然后这场比赛的T3教会我:如果实在调不出来,那就尽早写对拍,否则调死你!
铭记哀痛:2.5h+ 调分块最终 0 分!
若最优解可以通过合并得到,且时间允许,可以考虑区间DP。
区间DP的答案会和区间有关,这里的区间是广义的。
$2-2$
树上背包的其实可以理解为dp套dp,因为首先是父节点由子节点合并这一dp操作,其中又蕴含了背包的划分思想——每个子树都有代价和价值,因此合并子树就是 01 分组背包。
但是树上背包的复杂度真的玄学啊,上下界优化正在学习中……
开始学一些不一定用得上的数学。
排序不等式(大小搭配乘不如大配大小配小):
详细证明
接下来介绍一道与之相关的好题(可能 dp 的占比更大一点?)
P2647 最大收益
神题。
考虑选择了 $s$ 物品,所选的第 $i$ 个物品的价值为 $W_i$,代价为 $R_i$,那么收益为
在选取的物品一样的话,要使收益最大的选取顺序就应该使得 $\sum\limits_{i=1}^s(s-i)R_i$ 这部分最小,将其拆开
显然只有后半部分跟选取顺序有关,因此考虑将他最大化,那么总体就最小。不难发现这就是排序不等式所支持的形式,当 $R_i$ 递增时取最大。以上就是我们贪心思路的数学证明,按照 $R$ 递增的顺序来取可以使得在取得物品相同时受益最大。
接下来就是这题精彩的 DP 了。
按照 $R$ 递增的顺序,我们尝试设 $f_i$ 表示考虑了前 $i$ 个得到的最大收益,但这样是不行的,因为 $R_i$ 对答案的影响与选了多少个相关。因此我们要将状态升维,设 $f_{i,j}$ 表示考略了前 $i$ 个取了 $j$ 个的最大收益。但还是不行,因为 $R_i$ 带来的影响与未来的决策选了多少个有关,我们无法在阶段 $i$ 的时候就知道,也就是说这么设状态是有后效性的,无法转移。
由前往后没有办法了,但可以发现 $R_i$ 只会对 $i$ 往后的数的选取造成影响,而对以前没有关系。貌似是一种无前效性?于是我们逆向思维,由后往前:设 $f_{i,j}$ 表示以 $i$ 为第一个往后选了 $j$ 个的最大收益,那么这时 $R_i$ 的影响就是 $R_i\cdot(j-1)$ 了。所以我们这样子倒着 DP,就解决了后效性的问题。
至此本题结 这题
说实话,当在题解看到逆向DP的那一刻,有一种颅内高潮的感觉。这不禁令我联想到了在这道题所初见的那个名叫 “费用提前” 的DP优化技巧,令我觉得两者有着莫名的联系。当时就想,这题能不能也用费用提前来做呢?答案是否定的,因为费用提前的前提是 当前决策对未来的影响只与当前决策有关。而反观本题,$R_i$ 的影响是和后续的决策相关的,因此我认为不能用费用提前来做(当然,这种逆向DP 的方式我觉得就很像费用提前)。
这里埋个伏笔,以后一定要去学!
原来树上背包这种合并蕴含着这么多东西!上下界优化他来了!
还是拿出 这题,普通的树上背包是这么写的:
点击查看代码
1 | void dp(int x) |
显然这份代码对于每个节点都要 $O(nm)$,加上搜索遍历总复杂度为 $O(n^2m)$。但是我们其实枚举了很多不必要的状态:
若已经合并了的大小为 $S$,$sze_x$ 表示以 $x$ 为根的子树大小。
- 对于 $f_{u,j}$,若 $j>S+sze_u$ 则是无意义的。
- 对于 $f_{u,j-k}$,若 $j-k>S\iff k<j-S$ 则是无意义的。
- 对于 $f_{v,k}$,若 $k>sze_v$ 则是无意义的。
我们根据上述调整 $j$,$k$ 的枚举范围,就被成为上下界优化。最终代码是这样的:
点击查看代码
1 | void dp(int u){ |
小编也很难相信,但是事实就是如此,这份代码的复杂度上界骤然变成了 $O(n^2)$ 的了!
因为每次转移实际上都是两两子树合并的过程,也可以点对点合并的过程。经过上下界优化,所有不必要的状态和转移都被省去了,对于任意点对 $(a,b)$ 只可能在它们的 $\operatorname{lca}$ 处被合并一次,因此复杂度上界就是 $O(n^2)$ 的了。
但是我们看代码循环处还对 $m$ 取了 $min$,因此复杂度应该跟 $m$ 也有关系。事实上当 $m$ 小于 $n$ 的规模时,可以证明,这个 dp 的复杂度是 $O(nm)$ 的。
这 是一道针对上下界优化的题,也非常神,卡得非常紧。这里面还有一个 trick,因为直接开二维数组会 MLE,因此直接把二维拍成一维的就可以减少很多原本不必要的空间。
参考资料
$2-4$
树形DP神题。
$\large{\text{Solution}}$
按照套路往往会设 $f_{u,j}$ 表示在 $u$ 的子树内选了 $j$ 个黑点的收益最大值。但是这样的状态设计使得 $u$ 和其子树 $v$ 的答案之间的关系非常复杂,转移方程也极难推出。
引入一个非常巧妙的思路,当子树转移非常麻烦的时候,我们可以考虑利用边来转移。
显然我们可以把距离分解为路径,再把路径分解为边,那么这条边对整棵树最后答案的贡献就是它被经过的次数乘以它的权值。而边 $(u,v)$ 被经过的次数是好表示的,它只与 $v$ 的子树内黑点的个数有关——具体的,边 $(u,v)$ 总共会被黑点经过 $k\cdot(m-k)$ 次,$k$ 表示 $v$ 子树内的黑点个数。对于白点经过的次数则同理。
考虑到我们关心的只是最后整棵树的答案,对于子树的答案并不关心。因此我们设状态的时候不一定要拘泥于子树之内,可以将其对最后整棵树答案的贡献视作状态,这样限制就宽松很多了。结合通过边转移的思想,我们不难想出 dp:
设 $f_{u,j}$ 表示在 $u$ 的子树内选了 $j$ 个黑点能给最终答案带来的最大贡献,那么
其中 $W_{u,v}$ 表示边 $(u,v)$ 的权值,$tot$ 表示边 $(u,v)$ 将会被经过的次数,可以利用枚举的 $k$ 计算。
只需要换一种设计状态的方法和转移的思路,这道题就转化成了简单的树上背包问题。
P7393 「TOCO Round 1」Eternal Star
神仙题。
$\large{\text{Solution}}$
考虑构造一棵在根节点处取得最大点权 $k$ 且符合要求的树。对于根节点,能够让我们限制它的大小的,只有其子节点的点权和数量。因此我们调整子节点的这些信息就可使得根节点满足要求。
需要限制如下:
子节点的点权,肯定包含了 $1\cdots k-1$。
若子节点中没有权值为 $p$ 的,那么让根节点变为 $p$ 则可使得整棵树的最大值变成 $k-1$ 且不会产生矛盾,与我们的期望不符。
每种权值对应的子节点有多个。
若没有这层限制,我们当然可以没有顾虑的使得根节点变为 $p$,而原本权值为 $p$ 的子节点变为 $p+1$,根节点因此变小了(称这一些列操作为 C,下面将会用到)。但是题目中有着 “点权和最小” 这一要求,于是我们可以通过调整各种子节点的数量来规避这种情况。
具体的,我们设点权为 $p$ 的子节点的个数为 $x$ ,那么为了保持根节点大小不变,应该有 $k+px
综上,第 $p$ 种子节点至少要有 $k-p+1$ 个。为了使点数最少,我们取等。
通过以上方式建立子节点,即可确定一个值为 $k$ 的根节点。显然这些子节点也应该被其子节点确定,所以对于每棵子树则是子问题,递归处理即可。
该方法实际得分 55pts,错误的原因是建树所使用的节点过多。
优化
为了通过此题,我们需要让所用的总结点数更小,也就需要优化以上建树过程。
观察上述思路,貌似无懈可击,但是我们应该注意到特殊的第 $k-1$ 号子节点。若我们对 $k-1$ 节点进行限制二中的替换(即操作 C),那么实际上其实就是根节点 $k$ 和 $k-1$ 对调了一下——$k$ 依旧是整棵树中最大的节点且依旧可以成为根节点,无事发生,这个操作没有直接的影响答案。
也就是说,对调 $k-1$ 和 $k$ 没有我们想得那么严重,我们只需要使得 $k-1$ 下的子节点可以同样限制住 $k$ 即可保证答案。但是根据限制二得到的不等式,我们却建立了两个 $k-1$ 子节点,这就是一种浪费!
具体的,如果使用这个优化,我们要在原本的 $k-1$ 号子节点下按照对 $k$ 的限制方法,建立编号为 $1\cdots k-2$ 的子树(这是为了让这个位置既能限制 $k-1$ 也能限制 $k$ ,也就无惧操作 C),然后删掉多余的那棵 $k-1$ 子树。也就是说我们可以用根为 $1\cdots k-2$ 的这些子树来换掉一棵根为 $k-1$ 的子树。这显然是值得的,因为后者的大小远大于前者,这么一换总结点数就变小了。
将上述优化具象化,我们建树的方式变为:建立两棵对称的树,将其根连接,使得其左右两个根下的 $1\cdots k-2$ 个子节点能够满足对 $k$ 的限制。
至此,本题结束。
$\large{\text{Code}}$
实现上有一个细节,就是在递归处理子树的时候不能再使用上文的优化。因为用了优化后建的树的对称性,其最大值可以在两个根的位置变化(我们最终答案不关心最大值的位置所以可以使用,但是递归到子树的时候我们有必要做这个限制),这就会导致我们对祖先的限制都失效。因此优化只能在最开始使用。
点击查看代码
1 |
|
$2-5$
双倍经验。
$\large{\text{Solution}}$
根据 P7393 的 结论,我们可以构造出 符合题意且最大点权为 $k$ 的 节点最少的树。
发现当 $k=11$ 的时候节点数最小的树的规模就远大于 $5\cdot 10^4$ 了。因此这题只会出现点权为 $[1,10]$ 的树(但是数据过水貌似只有到 $4$ 的情况,显然可以构造出一组数据叉掉),于是可以直接写出 DP 。
设 $f_{u,i}$ 表示节点 $u$ 取值为 $i$ 的最小权值和,那么转移为
$\large{\text{Code}}$
点击查看代码
1 |
|
似乎很多人都觉得最大点权的上界是 $\log_2n+1$(甚至还有人证明了?),但其实做过 P7393 就会知道这个上界并非以那么简单的函数增长(貌似有人 oeis 都找不到那个序列),所以我们只能将其近似看做 $\log_n$ 。
P1879 [USACO06NOV] Corn Fields G
简单状压DP,记录一些小技巧
- 枚举 st 的子集可以这么写
1
2
3
4for(int i=st;;i=(i-1)&st){
...
if(!i) break;
} - 判断 test 是否有相邻的两个 1 可以这么写
1
2if((test&(test<<1))>0||(test&(test>>1))>0) yes
else no - 快速将二进制转为十进制当然可以用 bitset。
Floyd 算法太有东西啦!(为什么能去掉一维的证明可以参考 这里)
Floyd 基于动态规划的思想,在数据允许的情况下,处理两两点对之间距离相关的信息时有着独特的优势(也就是说适用于多源的情况)。
通常倍增相关的题,我们都需要用一个参数 $k$ 来表示 $2^k$,然后通过 $k-1$ 来转移(通常是合并两段的信息)。
显然跑路器的作用相当于将存在路径长度为 $2$ 的整数次幂的点对直接相连,然后在这个新图中跑最短路。而判断点对是否相连我们可以用倍增惯用的方法判断($2^{k-1}\to 2^k$)。
对于这道题,若 $i\to k$ 和 $k\to j$ 都有长度为 $2^{l-1}$ 的路径,那么显然 $i\to j$ 有 $2^l$ 的路径。于是联想到 Floyd ,设 $f_{l,k,i,j}$ 表示只经过 $1\cdots k$ 的情况下 $i\to j$ 是否有长度为 $2^l$ 的路径,转移如下:
可以舍去一维,原因同 Floyd。
然后将存在 $2$ 的整数次幂的点对之间连上边跑最短路即可。
$2-6$
WC2024 T1。
还记得去年 WC 24pts 就能铜牌,89 就 Au,今年居然给了一道送分题。
$\large{\text{Question}}$
一共有 $n~(1\le n\le 200)$ 道题目 和时间 $T~(1\le T\le 3\cdot 10^5)$ ,每道题有三种属性:$a_i\in\{0,1\}$,$1\le t_i \le 3\cdot 10^5$,$1\le v_i \le 3\cdot 10^5$,表示做完第 $i$ 题需要花费 $c_i$ 的时间,可以得到 $v_i$ 的分数。小 $A$ 会按照先从左到右做完 $a_i=0$ 的题目,再从左到右做 $a_i=1$ 的题目,如果做到完这题的时间超过 $t$ 则不得分。$a$ 是未知的,对于 $2^n$ 种 $a$ 问小 $A$ 能得到的分数和是多少?
$\large{\text{Solution}}$
我们并不关心具体的 $a$ 是怎么样的 ,所以可以考虑求出每道题对答案产生的贡献。而每道题的贡献就是他的分数乘以在不同的 $a$ 中能被选中的次数。因此我们求出对于每道题有共多少种 $a$ 使得这道题可以被选上即可。
我们分类讨论 $a_i=0$ 和 $1$ 的情况:
若 $a_i=0$:容易发现当 $j>i$ 时无论 $a_j$ 对第 $i$ 道题产生影响,所以后面的 $a_j$ 怎么选都可以,根据乘法原理, 最终贡献得乘上一个 $2^{n-i}$。
现在我们只需要考虑 $j<i$ 的 $a_j$ 即可,而容易发现只有当 $a_j=0$ 时才会对这道题有影响(因为我们做题是先做完 $0$ 再做 $1$)。设前面的题总共做题时间为 $S$,那么只有当 $S+t_i\le T$ 时我们才可以做第 $i$ 题。移一下项就变成 $S\le T-t_i$。
此时我们再回顾现在要解决的问题:选出一些 $j<i$ 令 $a_j=0$ ,若它们 $T_j$ 之和(即 $S$)小于 $T-t_i$ 则称为合法,要求一共有多少种合法方案。可以发现这就是一个背包问题,$t_j$ 就是费用, $T-t_i$ 就是背包的容量,方案数就是要求的东西,动态规划解决即可。
至此,我们求出当 $a_i=0$ 时第 $i$ 题的贡献: $v_i\cdot 2^{n-i}\cdot f_{i-1,T-t_i}$ ,其中 $f_{i,j}$ 表示在前 $i$ 道题中选若干道做总用时不超过 $j$ 的选法,按照 01 背包转移即可。
若 $a_i=1$:根据题意,对于 $j$ $<$ $i$ 无论 $a_j$ 是什么我们都要先完成 $j$ 才能轮到 $i$ 。所以当 $\sum\limits_{j=1}^{i-1}t_j+t_i>T$ 时第 $i$ 题不得分,因为做不了。否则,根据上述分析的经验可知,无论 $a_j$ 怎么选,$i$ 都是有贡献的,所以也要乘上一个 $2^{i-1}$。
而对于 $j>i$ 的题显然只有当 $a_j=0$ 时才会对贡献产生影响。那到底有多少种情况呢?可以发现这也是一个 01 背包计算方案的问题,原理同上面分析 $a_i=0$ 时一样。此时费用就是 $t_j$,背包容量就是 $T-\sum\limits_{k=1}^{i}t_k$。
所以此时第 $i$ 题的贡献为 $v_i\cdot 2^{i-1}\cdot g_{i+1,T-sumt_i}$,其中 $sumt_i$ 表示 $\sum\limits_{k=1}^{i}t_k$,$g_{i,j}$ 表示从 $[i,n]$ 这些题中选若干道使得用时和不超过 $j$ 的方案数。因为是从后面选所以要倒着背包。
至此,这道题就做完了,我们只需要 $O(n)$ 的处理出每道题的贡献然后相加即可。显然这个过程是可以和背包同时完成的,所以总复杂度时 $O(nT)$。
$\large{\text{Code}}$
点击查看代码
1 |
|
$2-7$
Hash 可以做到快速的判断两个字符串是否相等,可以高效处理字串信息。利用前后缀 Hash 甚至能处理回文子串问题。
哈希一般有以下种类:
unordered_map不会冲突但是常数极大,还会被卡成 $O(n)$ 查询。- 自然溢出,也就是对 $2^{64}$ 取模。常数小,随机数据不易出错,但可能会被刻意数据卡冲突。
- 单模数 Hash,值域相对较小,可以被生日攻击(也就是随机数据下易冲突)。
- 双模数哈希,值域大几乎不可能被卡,但是常数极大。
如果我们处理出了前缀 hash 数组
那么 $[l,r]$ 子串的 hash 就可以表示为
ps: 回文子串问题一般都是二分中间点。
比如说这道题 P3805 【模板】manacher。我们可以预处理出前后缀 hash,然后枚举回文子串的中间点,二分半径,check 函数就用预处理好的 hash $O(1)$ 判断左右两边是否相等即可。于是就可以用 $O(n\log n)$ 的复杂度处理这道题,需要加点最优化剪枝以及用自然溢出 Hash 才能卡过去。
但是,自然溢出哈希是 $\bmod~2^{64}$,是可以卡的。
$\large{\text{Hash Killer I}}$
自然溢出哈希无非就是这种形式:
对于 $B$ 为偶数的情况,显然有 $2^{64}\mid B^i~(i>64)$。也就是说这些大于 $64$ 的项取模后对 $\operatorname{hash}$ 的贡献都是 $0$。于是便有了构造思路:aaaaaa...aaa 和 baaaaa...aaa 。两个字符串除了第一个字母不同,其他均相同,且长度大于 $64$。
对于 $B$ 为奇数的情况,我们考虑使用 $\text{Thue~Morse}$ 序列攻击。
1 | const int Q = 10; |
以上算法的字符串 $S$ 按照 $\text{Thue~Morse}$ 序列的形式生成,$T$ 则是其反串。这两个字符串具有 $S\ne T,\operatorname{hash}(S)=\operatorname{hash}(T)$ 的特点,于是就把自然溢出哈希 hack 了。
我们从 $\text{Thue~Morse}$ 序列的另一种生成方式解释为什么能达到这种效果。
先列出一些定义:
- 下文所讨论的所有字符串的字符集均为 $\{$
a,b$\}$ - 定义 $S$ 的反串为 $\operatorname{not}(S)$,表示对其每个字符都分别取反。也就是
a$\to$b,b$\to$a - 对两个字符串进行 $+$ 操作表示将这两个字符串连接。
- $|S|$ 表示字符串 $S$ 的长度。
考虑有这么一个字符串列 $A$,其生成规则根据 $\text{Thue~Morse}$ 序列,如下:
- $A_1=$
a - $A_i=A_{i-1}+\operatorname{not}(A_{i-1})$
显然串列的每一项的长度都是呈指数增长的,即 $|A_i|=2^{i-1}$。我们尝试证明存在 $i$ 使得 $\operatorname{hash}(A_i)=\operatorname{hash}\left(\operatorname{not}(A_i)\right)$。
要制造哈希冲突实际上就是找到 $i$ 使得 $f_i\equiv 0\pmod{2^{64}}$,根据 $B$ 为偶数时候的思路,就是要构造使得 $f_i$ 具有至少 $64$ 个 $2$ 的因子。观察 $f$ 的通项公式,发现里面有一串连乘。因为 $B$ 为奇数,所以 $B^{2^{j-2}}-1$ 必为偶数,因此 $f_i$ 中至少具有 $i$ 个 $2$ 因子。所以,我们使用 $f_{64}$ 即可达成目的。
但是,由上述规则构造出来的 $|A_{64}|=2^{63}$,这是一个极其庞大的字符串,显然不能作为一个可行的输入进行 hack。
我们继续观察 $B^{2^{j-2}}-1$
可以发现它也是由一连串偶数相乘得到的。根据上述分析,$B^{2^{j-2}}-1$ 的因子中一共有 $j-1$ 个 $2$,也就是说 $f_i$ 中有 $\sum\limits_{j=2}^i(j-1)=\frac{i\cdot(i-1)}{2}$ 个 $2$。
所以只需要 $i\ge12$ 就可以有 $2^{64}\mid f_i$,此时 $|A_i|\ge 2^{11}$,非常具有实践意义,于是就把自然溢出 Hack 了。
根据上文所述的这种 $\text{Thue~Morse}$ 串的构造方式,我们也可以写出对应的代码。
点击查看代码
1 |
|
对于不知道 $B$ 的奇偶性的情况,我们只需要在构造的两个串的末尾加上 $64$ a 即可。
$2-8$
哈希确实可以干很多事呢,主要是因为他可以快速比较两个字符串,还可以快速处理子串哈希。
- 字符串匹配。利用 $O(1)$ 求子串哈希的方法,可以快速比较模式串与子串,做到 KMP 一样的 $O(n)$ 匹配。但是求不了 $\text{border}$。
- LCP 最长公共前缀。利用哈希可以快速比较子串的特点,而 LCP 具有可二分性,就可以二分来做了。具体的就是每次 check 都看看当前前缀是不是 LCP,若不是则
r=mid-1,否则l=mid+1。$O(n+\log n)$ - P3763 [TJOI2017] DNA 允许 $k$ 次失配的匹配。这个 KMP 就做不了了,但是哈希可以。处理容错匹配的具体方式就是每次都找 LCP,那么 LCP 后面一个字符就是失配的;然后再往后找 LCP 就可找到下一个失配,如此往复,找 $k$ 次以后就等于容错了 $k$ 次,然后判断是否匹配即可。$O(kn\log n)$
- $m$ 个字符串的最长公共子串(LCS)。同 LCP 一样 LCS 也具有可二分性。于是我们二分最长的长度,check 就是找出所有这个长度的子串然后放到哈希表里,求交集判断即可。$O(nm\log n)$
- 不同子串个数。利用哈希求 LCP 可以以多一个 $\log$ 为代价求出字符串的后缀排序。字符串的后缀的所有前缀覆盖了这个字符串的所有子串,因此排序后相邻两个后缀的 LCP 的和就是重复的子串个数。$O(n\log^2n)$
感觉哈希和二分结合起来就非常的巧妙了,以及排序找相邻这种套路,可以多往这方面思考。
利用 tarjan 那种对把有向图分解为树边和返祖边的方式可以用来找环。
例如: P2661 [NOIP2015 提高组] 信息传递、P2921 [USACO08DEC] Trick or Treat on the Farm G
$离散化,并查集$
打了 30 分钟的错解拿了 90pts……
看到这道题马上联想到了今年 noip T2 ,然后直接莽了一个拓展与并查集上去,分别维护相等的和不相等的两个域。调了一下发现居然有 90pts!但后来才发现被 Hack 了。
为什么不行呢?原因很简单,拓展与并查集是要在关系具有传递性的情况才能用的!比如说今年 T2,因为每个变量都是 bool 值所以不等号之间是有传递性的。但是这题不一样,$a\ne b,b\ne c$ 不能推出 $a\ne c$,也就是说同时具有不等关系的变量还是不能放在同一个集合内。
其实这题的正解更加简单,就是一个简单并查集。考虑约束关系的顺序无关紧要,因此我们先处理完等号再处理不等号。等号是可以传递的,因此把相等的两个数放入同一个集合内,然后再逐个判断不等关系是否成立即可。
有点想启动一个往事补完计划,把以前大赛中不会做的题都补了。
CSP 沉痛的记忆,考场想到了两种可以拿满分的思路,但是不知道为什么过不了大样例。
大概发现了,拆点最短路的特点是数据普遍小,限制有特点。
首先发现 $nk$ 是一个非常实际的数字,于是可以联想到拆点。考虑分层图,一共 $k$ 层,第 $i$ 层表示从起点到这一层的点的距离 $\bmod~k=i$。于是对于题目中的一条有向边 $(u,v,w)$ ,我们是这么连的:$(u_i,v_{(i+1)\bmod k},w)~i\in[0,k-1]$。在这个图上 $1_0$ 到 $n_0$ 的路径长度肯定是 $k$ 的倍数。在这个图上解决问题,就自然而然地帮我们省去了一个条件。
再考虑一个很重要的性质:旅游途中不能停但是起点可以停留这个条件和中途可以停是等价的。所以我们直接按照中途可以停来做即可。
$\large{\text{Solution1}}$
直接再这张分层图上面跑 dij 最短路即可。考虑到当前点 $u$ 的最短时间是 $dis_u$,若 $dis_u<w$ 就走不到 $v$ 了。于是我们就在这里等待 $\left\lceil \frac{w-dis_u}{k}\right\rceil\cdot k$ 秒再走即可(因为我们已经知道在起点等等价于在中途等)。
事实上,我考场思路其实没有想到分层图,而是利用类似设 $DP$ 状态的方式通过最短路算法来转移。我设 $dis_{u,i}$ 表示走到 $u$ 的时间模 $k$ 为 $i$ 的最短时间,然后用这样子的状态直接在原图上跑 dij 直接转移。其实这本质上还是分层图,到同一个点且余数相同的状态是重复的,因为其将来可能面临的决策都已经被遍历过了。
感觉这么写很巧妙,即实现了分层图对限制的化解,同时节省了分层图的建图过程。
点击查看代码
1 |
|
$\large{\text{Solution2}}$
一个非常有意思的思路:我们可以二分开始时间,然后往后直接跑 BFS 判断能否到 $n$ 最后选时间最短的即可。但这个算法是 错误的 ,因为我们无法保证正向跑 BFS 得到的路程加上开始时间这个函数是单调递增的,因此不能用二分。
我们发现就是 当小于 $w$ 时边不能走 这个条件限制了二分的发挥,很烦。然后我就在题解区里发现了一个很巧妙的转换:考虑已经知道了结束时间为 $x$ ,那么我们建立反图从 $n_0$ 开始在分层图上跑最短路得到 $dis_u$。那么原本的限制在反图上就变为了当 $x-dis_u+1\ge w$ 可以转移到 $v$。移一下项可得 $dis_u<x-w$ 时可转移。这就等于给了一个上界,那么最短路能转移的位置肯定时最多的,也就是最优的,因为它最短嘛。所以这时候我们在反图上跑最短路的正确性就有保证了,于是二分结束时间 $x$ 即可。
点击查看代码
1 |
|
$2-10$
打了一场 luogu Rated 比赛的重现赛,很简单,大概 2h 能 AK,可惜当时没报名。
还是学到了一些有趣的东西的呢,以后再补吧。
update at 2-12 :现在来补吧。
$\large{\text{Solution}}$
提供一种适合赛时小白使用的方法。
看了一下题解,大佬们都用恐怖的数学证明了以下做法的结论,但是往往有时候打比赛如果不是实力过硬,就并没有那么多时间来证明。
因此对于这种限制相对简单的数列题,我们可以直接暴力,生成题目中的序列然后在上面找规律。一般都能找到的,因为其实通过数学做的一切对算法优化,投影到实际其实就是把一些冗余计算给省略了——所以这种省略冗余的操作肯定能用眼睛找规律来做啦!
肯定要对答案进行一定的转化(否则干嘛放 T3)。根据题目可以发现
显然前面的一个连乘可以直接预处理一个前缀积数组来 $O(1)$ 解决掉,那么问题就转化为求 $s$ 的乘积了。
我们写出暴力,将样例中的前 $5$ 个序列 $s$ 跑出来观察,发现是这样的:
1 | 1 |
我们可以发现,随着数据规模的增大,$s$ 后面应该是跟着一大坨重复的数的。这一点就非常的适合优化了,因为这意味着对于后面重复的一堆数我们可以只算一次就得到他们的乘积,当然是用快速幂了。
多跑几组更大的数据发现这个规律没错, $s$ 后面一定会有大量冗余,真正不同的数字只有最多 $1500$ 个(这个是用暴力跑出来得到的,亲测这种方法在赛时非常好用)。所以算法思路就很明确了,对于不同的数字我们暴力计算其乘积,相同的数字我们用快速幂计算其贡献,就可以得到 $\prod\limits_{i=1}^n s_i$,于是再乘上一个预处理出来的前缀积 $mul_n$ 就可以得到 $\prod\limits_{i=1}^n h_i$ 啦。
时间复杂度大概是 $O(1500\cdot T)$ ,那个 $1500$ 具体怎么来的可以看前面大佬们的题解,赛时的时候就不用深究啦,肯定能过。
$\large{\text{Code}}$
具体实现参考下面这份代码。
点击查看代码
1 |
|
虽然但是,打表找规律真的在这种没啥式子但限制简单的数列题中很好用呢。
证明 上述结论的时候学到了几个有意思的小技巧。
- 要证明 $x=\left\lceil\dfrac{a}{b}\right\rceil$,向上取整非常令人讨厌,我们可以用不等式将其转化掉。也就是证明:$x\ge \dfrac{a}{b} >x-1$。
- 要证明当 $i\ge x$ 时,有 $f(i)\le 0$。$f(x)$ 的定义域是正整数域。可以尝试找出 $i$ 每次增长对 $f(i)$ 的上限,即证明 $d(i)=f(i+1)-f(i)\le y$,类似于求函数的差分,此时原命题就变为证明差分函数的前缀和 $\le 0$。这种证明神似 积跬步以至千里 的感觉。想要到千里,那么就要找出跬步。
简单贪心。
题意要求以 AC 数作为第一关键字,罚时作为第二关键字排序。因此为了使能榜一的尽量多,AC 数多的坑定不能比 AC 数少的先结束比赛,所以先按照 AC 数递增来排序。
可以发现 WA 到底产生在哪里并不重要,因为最终都会带来 $x\cdot t_i$ 的贡献,因此我们直接把 WA 全部放在结束的时候即可。
对于 AC 数相同的选手,罚时少的不应该比罚时多的先结束比赛,所以结束的时候应该按照罚时递减来结束。
但是做题过程中,每做一道题无论是否 WA 都会产生 $i$ 的罚时,因此可能会出现原本罚时少的因为晚做所以最后罚时多了的情况。但是注意到只有最后的一次提交会影响结束顺序,前面的提交任意即可。因此对于非结束的提交,我们按照罚时递增来做,这样可以保证罚时少的到最后还是少,罚时多的到最后还是多,保证了罚时的相对大小关系。
趁机学会用 SPJ 来调试了。
SPJ 会调用 testlib.h,需要从 这里 下载并将其内容放入 SPJ 同级文件夹内。
SPJ 的代码就是 checker.cpp 文件,用命令 g++ -fno-asm -std=c++14 -O2 命令来编译得到 checker.exe。然后通过指令 checker.exe in.txt out.txt ans.txt 来分别传入 输入 输出 和标准答案文件,checker.exe 会根据标准答案来判断输出是否合法。
你当然可以通过修改 SPJ 获得更详细的错误信息。
$2-15$
分层图最短路的实质其实就是给 dis 数组增加维度罢了,直接用 DP 转移的思路来求最短路就能很好的解决类似问题了。
$\text{Solution1:}$
我们跑 dij 的时候可以把 dis 变为 dis[u][1/2] ,表示从某个关键点出发到点 $u$ 的最短路,以及从另一个不同的关键点出发,到点 $u$ 的次短路。只需要在转移的时候按照这个思路判断一下,然后直接
跑 dij 就实现了一个神奇的分层图。因为关键点的最短路肯定是从它自身出发的 $0$,因此关键点中次短路的最小值就是答案,复杂度 $O(n\log n)$。
最短路和次短路的转移不是割裂的,因此只要最短路转移不成功就可以尝试用这条边去松弛次短路。(具体就体现在 vis 数组的使用,我在这上面死了很多次。)
摸索出了优先队列优化 SPFA,但好像是假的,可以参考 这里。
update:好像没假,只有负权图可以卡欸……
$\text{Solution2:}$
该算法来自题解区,非常逆天。
二进制分组。
如果我们按照某种方式把关键点分成 $A$ 组和 $B$ 组,那么从所有的 $A$ 点出发跑 dij 就能得到到 $B$ 点的最短距离。因此题目要求的两关键点间的最短距离,实际上就是要找到一种分组方式,使得两两关键点一定有机会分到不同的组。当然这种分组的方式分法也不能太多,否则复杂度就爆了。
接下来就是一个很秀的操作了:考虑两关键点编号在二进制位上肯定至少有一位是不同的(否则不就是同一个点了吗),因此我们按照每个二进制位 01 分组,一共会分 $\log n$ 次,算上 dij 总共复杂度是 $O(n\log^2 n)$。
无论是将题目要求分组解答还是联系二进制,这些思路都是非常神奇。
其中涉及到 dij 的伪多源版本,就是从多个起点同时出发到达多个终点。具体的可以参照网咯流建图,将所有起点同一个超级源点,所有终点同一个超级汇点连起来,就变成了普通最短路。
$\text{Solution3:}$
考虑正反图从关键点出发分别跑两遍 dij,用 $dis_{u,1}$ 表示从某个关键点到 $u$ 的最短距离,用 $from_u$ 表示这个关键点;$dis_{v,2}$ 表示从点 $v$ 出发到某个关键点的最短距离,用 $to_v$ 表示这个关键点。
现在枚举有向边 $(u,v,w)$,若 $from_u\ne to_v$ 则尝试用 $dis_{u,1}+w+dis_{v,2}$ 更新答案。时间复杂度 $O(n\log n)$。
但是我在思考这个思路的时候遇到了问题:如果 $v$ 到多个关键点的最短距离相同,而 $to_v$ 只能被其中一个更新,那会不会因为这样导致 $from_u=to_v$ 而答案无法被这条边更新因此出错呢?
这种情况是会出现的,但 ans 不会因此变得更劣,因为最优路径中一定有相邻的两点颜色不同,于是答案一定会被最优解更新。
考虑证明,若正确答案选择的关键点是 $x$ 和 $y$,那么分析 $x\to y$ 这条最短路径:
- 若 $x\to y$ 只有一条边,那么这条路径上的边显然不会有 $from_u=to_v$ 的情况出现,于是得到正确答案。
- 若 $x\to y$ 有两条边,设其位 $(x,z)$ 和 $(z,y)$ ,显然 $x,z$ 和 $y,z$ 肯定有一对颜色是不同的,于是答案能被更新。
- 若 $x\to y$ 有超过两条边,那么可以考虑假设 $from_u=to_v$,然后一步步往前推,最后一定会得到矛盾。因此肯定能更新答案。
练习了一轮分层图最短路,发现核心思路都不是在思考如何分层——其实转用动规的思想,设计 dis 数组考虑拆点转移会更加方便且好实现一些。如果早点学习 2023CSP-J T4 就肯定能写出来了吧。